
A lot of websites are generating data which could be really useful outside a web browser. Having the weather shown on your smartphone's lock-screen, the delay until your next bus… How can we use this from an application?
This article will explain what's behind these hidden data flows, and how to use them. For this purpose, I'll use Trakt.tv as an example. If you don't know it: Trakt allows you to manage your movie/TV series library, keep track of watch progress, your ratings, comments… and see those of other people.
Some code will show how to send such requests. It will be written in Ruby.
Planet of the APIs
The concept behind these data flows is called an API - Application Programming Interface. While API is a pretty generic term, in this specific case, it specifies how a website will expose its data (and possibly receive some, too) to (and possibily from) a client. A client can be any kind of application sending requests to the website (the server). Not to be confused with the user, which uses a client, which in turn sends requests to a server.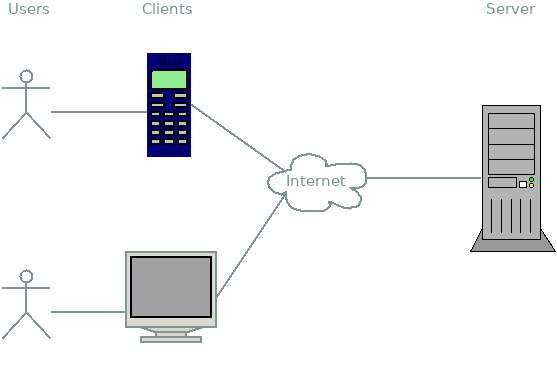
For websites, two data formats are mostly used: XML - eXtensible Markup Language - and JSON - JavaScript Object Notation. Both serve the same purpose: presenting data in a computer-readable way. For example, this is how you could represent a movie in JSON:
Sample representation of a movie
{
"title": "Sharknado",
"year": 2013,
"runtime": 86,
"tagline": "Enough said!",
"overview": "A freak hurricane hits Los Angeles, causing man-eating sharks to be scooped up in tornadoes and flooding the city with shark-infested seawater. Surfer and bar-owner Fin sets out with his friends Baz and Nova to rescue his estranged wife April and teenage daughter Claudia",
"genres": [
"Science Fiction",
"Horror"
]
}Trakt's API uses JSON. As a matter of fact, this JSON bit comes from the API. You can find the same details about the movie directly on Trakt. It's just not useable from an application directly.
Trakt's API documentation is available here.
REST in pieces
If an API was made for only one goal - like indicating the weather in a given city -, it would be pretty simple: just access an URL like http://myapi.net/weather?city=Toulouse , return the corresponding data, done. However, for a fully-featured API, dealing with multiple elements like movies, series, series episodes, users… you need something a little more complex than that. And that's where concepts like REST - Representational state transfer - come to help.
REST is a list of five (and an optional sixth) constraints for the API architecture:
- Client/server oriented: data is stored on a server, and displayed on a client
- Stateless: every request from a client must contain all the information needed to be handled by the server. If any kind of state management is needed, the client is in charge
- Cacheable: responses from the server must specifiy how long they are valid (we'll get back to that a bit later)
- Uniform interface: this one is a list of four sub-constraints to guide the API organization:
- Identification of resources: the way an item is identified in a response should be consistent with the request, not with the database behind the API
- This identification must be sufficient: a client must be able to modify or delete a resource from the identification given by the server
- Self-descriptive requests: a request must contain everything needed to be processed by the server. Similar to the stateless constraint
- Simple client transitions: if a client has to send a separate request to access more related information, the way to get it must be described in the initial response
- Layered system: a request must be able to be as specific as possible, so the server doesn't have to send its full database content when replying. A client can ask for a list of movies, but can also ask for details about a specific one if it's just interested in this one
- Code on demand (optional): the server can send a bit of script, which will be run by the client, either to limit the server's load, or to occasionally change the client behaviour.
A REST architecture has multiple advantages. The simple fact of being stateless is probably the most important to the end user: the client doesn't have to maintain a connection to the server between requests, which allows a huge reduction in power consumption on mobile devices. It also simplifies the load-balancing on the server side (any server can process any request without the need of an existing context).
From a developer point of view, a layered architecture tends to make the system easier to maintain, and easier to use.
Doctor Who?
There are many aspects regarding the authentication when talking about an API. A common need is to identify the user. Who's trying to mark this movie as watched? Another one is to identify the application using the API. A user may want to see a list of applications accessing his account, remove access to a specific one…
Identifying the application is pretty easy. For APIs where this identification is in place, the developer must register the application. The website then provides a unique identifier for this application. This is called an API key. This key must be placed within every request from this application. The API website can reject every request without a valid key, revoke a specific key…
Finding Nemo
We now know how a website exposes its data, how to parse them, and how they are organized. Here's a concrete use case: we want to retrieve the list of the directors of the Finding Nemo movie.
We first need to find the movie. We'll use the search/movies API method. It needs three parameters, the last one being optional:
- format: how the response should be formated. Only JSON is supported for this method
- apikey: we need to identify ourselves as a Trakt.tv API user
- query: what are we looking for?
- limit: number of results at max. Defaults to 30
And here's how the request should look like: http://api.trakt.tv/search/movies.format/apikey?query=query&limit=limit
Let's call it in Ruby:
search/movies
require 'cgi'
require 'json'
require 'net/http'
require 'uri'
format = 'json'
api_key = '1234567890abcdefghijklmnopqrstuv'
movie_to_search = 'Finding Nemo'
# CGI::escape is needed to convert special characters from the movie name
# In this case, we need to escape the space
uri = URI.parse "http://api.trakt.tv/search/movies.format/api_key?query=CGI::escape movie_to_search"
# Send the request to the server
response = Net::HTTP.get_response uri
# Parse the response as a JSON object
json_response = JSON.parse response.body
# Print it nicely
puts JSON.pretty_generate json_responseAnd here's the result, truncated to the first two movies:
search/movies result for Finding Nemo
[
{
"title": "Finding Nemo",
"year": 2003,
"released": 1054278000,
"url": "http://trakt.tv/movie/finding-nemo-2003",
"trailer": "http://youtube.com/watch?v=SPHfeNgogVs",
"runtime": 100,
"tagline": "There are 3.7 trillion fish in the ocean, they're looking for one.",
"overview": "A tale which follows the comedic and eventful journeys of two fish, the fretful Marlin and his young son Nemo, who are separated from each other in the Great Barrier Reef when Nemo is unexpectedly taken from his home and thrust into a fish tank in a dentist's office overlooking Sydney Harbor. Buoyed by the companionship of a friendly but forgetful fish named Dory, the overly cautious Marlin embarks on a dangerous trek and finds himself the unlikely hero of an epic journey to rescue his son.",
"certification": "G",
"imdb_id": "tt0266543",
"tmdb_id": 12,
"images": {
"poster": "http://slurm.trakt.us/images/posters_movies/647.4.jpg",
"fanart": "http://slurm.trakt.us/images/fanart_movies/647.4.jpg"
},
"genres": [
"Animation",
"Comedy",
"Family"
],
"ratings": {
"percentage": 85,
"votes": 7917,
"loved": 7668,
"hated": 249
}
},
{
"title": "Finding Dory",
"year": 2016,
"released": 1466146800,
"url": "http://trakt.tv/movie/finding-dory-2016",
"trailer": "http://youtube.com/watch?v=q2a3tS7zNcU",
"runtime": 0,
"tagline": "",
"overview": "Sequel to the 2003 Pixar film 'Finding Nemo'",
"certification": "G",
"imdb_id": "tt2277860",
"tmdb_id": 127380,
"images": {
"poster": "http://slurm.trakt.us/images/posters_movies/209152.1.jpg",
"fanart": "http://slurm.trakt.us/images/fanart_movies/209152.1.jpg"
},
"genres": [
"Adventure",
"Animation",
"Comedy",
"Family"
],
"ratings": {
"percentage": 100,
"votes": 4,
"loved": 4,
"hated": 0
}
},
// ...
]Look at the first one: it is the movie we were looking for! Now, we want to display its details. To achieve this, we'll need to use another method: movie/summary. Here are its parameters:
- format and apikey: same as above
- title: Could be the last part of the
urlattribute we got earlier (for Finding Nemo, it would befinding-nemo-2003), the IMDB ID (imdb_idattribute), or the TMDB ID (tmdb_idattribute). We'll use the IMDB ID.
Here's how the request should look like:
http://api.trakt.tv/movie/summary.format/apikey/title
movie/summary
require 'cgi'
require 'json'
require 'net/http'
require 'uri'
format = 'json'
api_key = '1234567890abcdefghijklmnopqrstuv'
movie_to_search = 'Finding Nemo'
# CGI::escape is needed to convert special characters from the movie name
# In this case, we need to escape the space
uri = URI.parse "http://api.trakt.tv/search/movies.format/api_key?query=CGI::escape movie_to_search"
# Send the request to the server
response = Net::HTTP.get_response uri
# Parse the response as a JSON object
json_response = JSON.parse response.body
# Extract the IMDB ID of the first result
imdb_id = json_response.first['imdb_id']
# Request the summary
uri = URI.parse "http://api.trakt.tv/movie/summary.format/api_key/imdb_id"
response = Net::HTTP.get_response uri
json_response = JSON.parse response.body
# Print it nicely
puts JSON.pretty_generate json_responseAnd the truncated output:
movie/summary for Finding Nemo
{
"title": "Finding Nemo",
"year": 2003,
"released": 1054278000,
"url": "http://trakt.tv/movie/finding-nemo-2003",
"trailer": "http://youtube.com/watch?v=SPHfeNgogVs",
"runtime": 100,
"tagline": "There are 3.7 trillion fish in the ocean, they're looking for one.",
"overview": "A tale which follows the comedic and eventful journeys of two fish, the fretful Marlin and his young son Nemo, who are separated from each other in the Great Barrier Reef when Nemo is unexpectedly taken from his home and thrust into a fish tank in a dentist's office overlooking Sydney Harbor. Buoyed by the companionship of a friendly but forgetful fish named Dory, the overly cautious Marlin embarks on a dangerous trek and finds himself the unlikely hero of an epic journey to rescue his son.",
"certification": "G",
"imdb_id": "tt0266543",
"tmdb_id": 12,
"rt_id": 9377,
"last_updated": 1405432489,
"poster": "http://slurm.trakt.us/images/posters_movies/647.4.jpg",
"images": {
"poster": "http://slurm.trakt.us/images/posters_movies/647.4.jpg",
"fanart": "http://slurm.trakt.us/images/fanart_movies/647.4.jpg"
},
"top_watchers": [
{
"plays": 91,
"username": "Damon_old",
"protected": false,
"full_name": "",
"gender": "",
"age": "",
"location": "",
"about": "",
"joined": 0,
"avatar": "http://slurm.trakt.us/images/avatar-large.jpg",
"url": "http://trakt.tv/user/Damon_old"
},
// ...
],
"ratings": {
"percentage": 85,
"votes": 7917,
"loved": 7668,
"hated": 249
},
"stats": {
"watchers": 2135,
"plays": 5541,
"scrobbles": 5357,
"scrobbles_unique": 1975,
"checkins": 184,
"checkins_unique": 163,
"collection": 12633
},
"people": {
"directors": [
{
"name": "Andrew Stanton",
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
},
{
"name": "Lee Unkrich",
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
}
],
"writers": [
{
"name": "Andrew Stanton",
"job": "Screenplay",
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
},
// ...
],
"producers": [
{
"name": "Graham Walters",
"executive": false,
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
},
{
"name": "John Lasseter",
"executive": true,
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
}
],
"actors": [
{
"name": "Albert Brooks",
"character": "Marlin",
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
},
{
"name": "Ellen DeGeneres",
"character": "Dory",
"images": {
"headshot": "http://slurm.trakt.us/images/avatar-large.jpg"
}
},
// ...
]
},
"genres": [
"Animation",
"Family",
"Comedy"
]
}We have our directors in the people object, which contains a directors array. Let's extract it:
Extract Finding Nemo's directors
require 'cgi'
require 'json'
require 'net/http'
require 'uri'
format = 'json'
api_key = '1234567890abcdefghijklmnopqrstuv'
movie_to_search = 'Finding Nemo'
# CGI::escape is needed to convert special characters from the movie name
# In this case, we need to escape the space
uri = URI.parse "http://api.trakt.tv/search/movies.format/api_key?query=CGI::escape movie_to_search"
# Send the request to the server
response = Net::HTTP.get_response uri
# Parse the response as a JSON object
json_response = JSON.parse response.body
# Extract the IMDB ID of the first result
imdb_id = json_response.first['imdb_id']
# Request the summary
uri = URI.parse "http://api.trakt.tv/movie/summary.format/api_key/imdb_id"
response = Net::HTTP.get_response uri
json_response = JSON.parse response.body
# Extract directors
json_response['people']['directors'].each do |director|
puts director['name']
endAnd here's the output:
Finding Nemo's directors
Andrew Stanton
Lee UnkrichWe can check the result directly on Trakt: looks like we're good!
Cache me if you can
Now, we know how to retrieve data about movies. We can build an awesome application, using Trakt.tv lists to keep a list of movies we want to watch. However, because we're spending so much time to work on this application, we don't have any time left to watch thoses movie. Every time we fire up the application, we fetch, for every movie, all the information back from the API. Even if we're pretty sure the data hasn't changed (I mean, have you ever seen a movie director changing after it has been released?), we use bandwith, data plan on a smartphone, battery…
This is bad.
We need to find a way to save this kind of data offline to use less bandwith, but we also need to refresh these data if they have been changed on the server. This is called caching.
A web cache stores copies of documents passing through it; subsequent requests may be satisfied from the cache if certain conditions are met. -- Wikipedia
There are multiple ways to cache accesses to an API. The simplest is to rely on HTTP cache if the API is accessed over HTTP: the HTTP standard includes cache-related headers, and the API should tell us how long we can keep the data cached. Until this delay has expired, we can use our offline copy of the data. When it's out of date, we simply re-fetch it.
Another mechanism, probably more convenient for an API like Trakt, is the ETag. An ETag identifies a specific version of an answer. When we make a request (for example, ask for a movie details), the server can add an ETag header. If it's present, we should store it alongside an offline copy of the movie details. Next time we need to use these details, we should ask the server: "Hey, I have a copy of these details matching this ETag! Have you anything newer for me?" If there is a new version available, the server will send it over, with a new ETag. We have lost two dozen bytes of bandwith. Damn. However, if the details haven't changed, the server will simply answer with an empty Not Modified response. And that will be most of the time, for this kind of request. Hooray for the planet. And our batteries.
There are tons of ways of caching content. Nearly every API will use a different mechanism, suitable to its data lifespan.
On a fast ADSL connection, a simple request on the Trakt.tv API takes a couple hundred milliseconds. If you run multiple queries in parallel, it will be slower. Now, imagine on a 3G network. Cache does matter.
Requiem for an API
As you can see, once an API has been written, using it is pretty easy. With standards like JSON and XML, REST… they basically all work in the same way.
The crucial part to develop an application is, however, the actual availability of an API. Not all sites provide one. On the other hand, some sites provide excellent ones, some of them being just an API client themselves (that's a principle called dogfooding).
Code samples presented here are in Ruby, but you can of course use any language you want to access to an API (well, good luck to use an API in brainfuck). Some API providers maintain library in several languages to ease the use of their API, providing high-level objects (example here, a library provided by GitHub to access its API in Ruby).
Comments